|
CERN openlab II - Platform Competence Centre
Virtualization
Technology Overview
There are different approaches to virtualizing hardware. The approach taken by the
Bochs x86 emulator,
is to translate each instruction executed in the domain of
the guest OS into equivalent operations executed in the VM.
Translating each instruction leads to a significant overhead
compared to native execution.
The approach
taken by VMware is to
translate only the instructions that need to be translated.
Instructions that belong to the guest OS kernel are
translated and executed in a VM, while instructions that
belong to user space applications in the guest OS's domain,
are executed natively. Blocks of translated instructions can
be reused in order to reduce the overhead of translation.
This method yields better performance than pure translation.
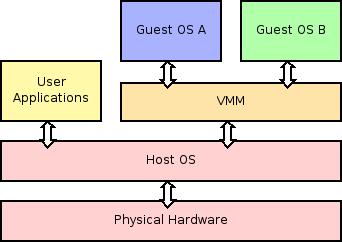
The Virtual Machine Monitor (VMM) runs alongside the host's
user space applications on top of the host OS kernel.
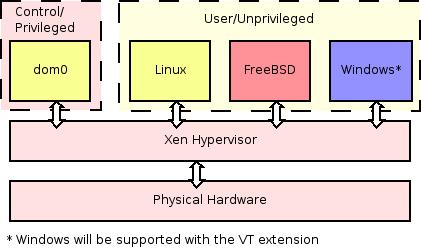
Xen takes a novel approach by eliminating sensitive
instructions directly in the guest OSs' original source
code, which is called para-virtualization. These
instructions are replaced with equivalent operations or
emulated by replacing them with hypercalls, which
call equivalent procedures in the VMM, or hypervisor.
The hypervisor runs as the most privileged kernel, while
guest OS kernels run less privileged on top of the
hypervisor. This method yields close-to-native performance.
| 